

حدود 80 درصد حجم داده دنیا در دو سال اخیر تولید شدهاند. به این حجم از دادههای تولید شده بزرگداده گفته میشود. امروزه کسبوکارهای مختلف با توجه به نوع کسبوکار و نیاز مشتری به دنبال استخراج دانش از این دادههای تولیدشده در کسبوکارشان هستند. استخراج دانش از دادهی خام با پیدایش زیرساختها و تکنولوژیهای جدید در پردازش داده امکانپذیر شده است و سرویسهای مختلفی با توجه به نیازهای گوناگون پردازشی بهوجود آمدهاند. این سری نوشتار زیرساخت پردازش داده و ابزارهای پردازشهای داده محور را معرفی میکند.
بزرگداده یا Big Data چیست؟
به حجم انبوهی از داده تولیدشده بزرگداده (کلان داده) گفته میشود اگر چند ویژگی اصلی را داشته باشد:
- Variety: این نوع دادهها از منابع مختلفی تولید میشوند، از تراکنشهای بانکی و لاگ(گزارش)های وبسایتها گرفته تا سنسورها. همچنین انواع داده به دو دسته تقسیم میشوند: دارای ساختار یا بدون ساختار مثل فیلم و عکس که نمیتوان آنها را در پایگاهدادههای معمولی نگهداری کرد.
- Velocity: سرعت رشد تولید این نوع دادهها بسیار زیاد است. سیستمهایی هستند که به صورت لحظهای در حال تولید داده هستند. گاهی لازم است این حجم داده به صورت بلادرنگ (real-time) پردازش و آنالیز شود.
- Volume: حجم این نوع داده به اندازهای است که در ابزارهای ذخیرهسازی معمولی قابل نگهداری نیستند. (به اندازه چند صد پتا بایت)
در واقع این موارد شاخصههای تعریف بزرگداده هستند. همین ویژگیها چالشهای جدیدی در زمینه جمعآوری، ذخیره و پردازش و تحلیل بزرگدادهها بهوجود آورده و باعث شده که ابزارهای سنتی کار با داده پاسخگوی نیازهای جدید نباشند. وجود چنین چالشهایی و کاربردهای Big Data باعث ایجاد زیرساخت پردازش داده به صورت امروزی شده است.
زیرساخت پردازش داده چیست؟
برای درک بهتر زیرساخت پردازش داده، باید با مفاهیم سیستم توزیع شده آشنا شوید. سیستمهای توزیعشده زیرساخت اساسی در مدیریت بزرگداده است. به طور ساده و خلاصه مولفههای یک شبکه توزیعشده این است که نودها در این شبکه با هم در ارتباط هستند و هریک از آنها قسمتی از کل داده را نگهداری میکنند. Taskهای یک پردازش بر روی نودها توزیع شده و به این صورت پردازش حجم عظیمی از داده به صورت موازی و توزیعشده انجام میشود.
الگوریتم MapReduce
این نوع از محاسبه اولین بار توسط گوگل با معرفی الگوریتم MapReduce آغاز شد. این الگوریتم در یک فاز پردازش را بر روی نودهای یک کلاستر، که شبکهای از نودهای متصل به هم هستند، توزیع کرده و در فاز بعد دادههای مربوط به پردازش های جزیی را تجمیع میکند. معرفی این الگوریتم انقلاب عظیمی در پردازش داده ایجاد کرد. روشهای سنتی با ارسال درخواست (query) به نودهای یک شبکه، دادهی مورد نظر را به سرور انتقال داده و محاسبه را انجام میدادند اما پردازش بزرگداده با چنین هزینهایI/O بسیار بالا بود و اصلا مقرون به صرفه نبود.
در شیوه نوین معرفیشده توسط گوگل، به جای انتقال داده بین نودها، پردازش به نودهای حاوی داده (به صورت محلی) ارسال شده و پردازش انجام میشد. بدین ترتیب پردازش مجموعه بزرگی از دادهها به صورت موازی و کارا انجام میگرفت. در شبکهای از نودهای به هم متصل (زیرساخت پردازش داده) و توزیع پردازش به نزدیکترین نود حاوی داده، امکان ایجاد سرویسهای آنالیز داده بهوجود میآید که قابلیت در دسترس بودن همیشگی سرویس، آنالیزهای بلادرنگ، ریکاوری مشکلات ایجادشدهی سختافزاری و دیگر چالشهای بزرگداده مانند مدیریت و ذخیرهسازی را امکانپذیر میکند.
معرفی زیرساختهای پردازش داده
زیرساخت Hadoop چیست؟
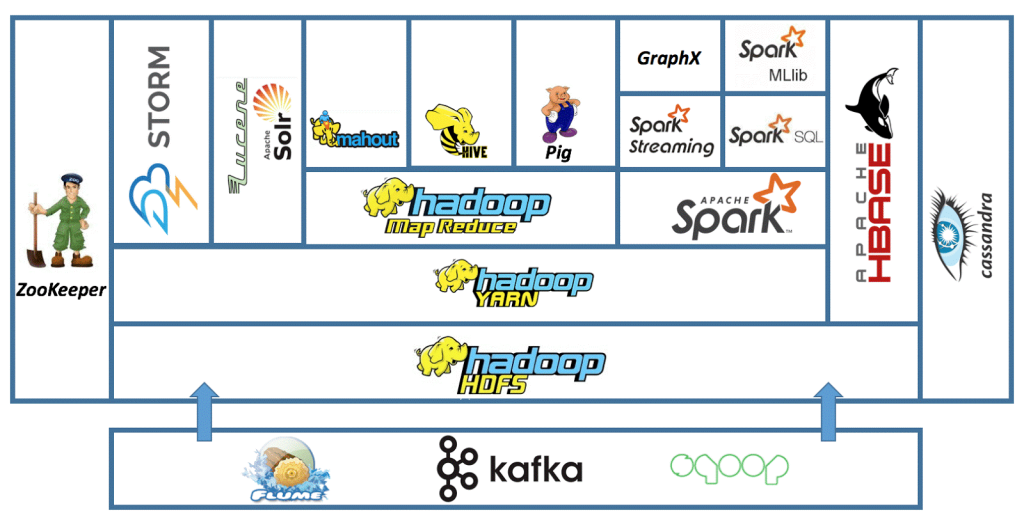
بزرگترین و مهمترین زیرساخت پردازش داده اکوسیستم (Hadoop)هدوپ است. این چارچوب متن باز (open-source) نوشتهشده با زبان برنامهنویسی جاوا، با داشتن سیستم فایل توزیعشده مختص به خود HDF (یا همان Hadoop Distributed File System) قادر به پاسخگویی به چالشهای مدیریت، ذخیرهسازی و پردازش بزرگداده است.
اکوسیستم Hadoop از چند بخش تشکیل شده:
- Hadoop Common شامل کتابخانهها و امکانات مورد نیاز سایر بخشها
- YARN (یا همان Yet Another Resource Negotiator) مدیریت منابع کلاستر را برعهده دارد. YARN همواره با در نظرگرفتن منابع آزاد، taskهای مربوط به application کاربر را برای اجرای موازی برروی نودها زمانبندی (Schedule) میکند.
- MapReduce لایه پردازشی این اکوسیستم است که منطق برنامه کاربر را به taskهایی بر اساس مدل map و reduce تبدیل و اجرا میکند.
فایلهای بزرگ در چارچوب هدوپ به blockهای داده تقسیم شده و به روی کلاستر قرار میگیرند. برنامه کاربر بعد از تقسیمشدن به فازهای map و reduce، ابتدا در فاز اول (map) با توجه به منابع مورد نیاز برای اجرای موازی و منابع در دسترس، به تعدادی task پردازشی تبدیل میشود و برای اجرا به نودهای آزاد ارسال میگردد. پس از اجرای taskهای فاز اول، نوبت به اجرای taskهای فاز دوم (reduce) میرسد و در نهایت داده نهایی بروی HDFS ذخیره میگردد. به این صورت امکان آنالیز داده با الگوریتم هایی بر اساس map و reduce، در حجم بزرگداده وجود خواهد داشت.
برای تجربهی زیرساخت پردازش داده، دست به کار شو!
برای شروع تجربه ایجاد یک زیرساخت پردازش داده بر اساس یک سیستم توزیع شده برای پردازش داده به دو روش میتوانید عمل کنید:
روش اول: به صورت دستی Hadoop را نصب کنید.
در این روش بخشهای کلاستر پردازشی مورد نظر را بر اساس نیاز باید به صورت لایه لایه نصب و پیکربندی کنید. در ابتدا بعد از نصب Hadoop پیکربندیهای لازم را انجام دهید و سرویسهای فایلهای داده را به HDFS منتقل کنید. برای این کار لازم است دید سیستمی خوبی داشته باشید تا بتوانید براساس منابع پردازش در دسترس، برای بخشهای مختلف Hadoop پیکربندیهای مناسبی انتخاب کنید. این روش بهترین تجربه استفاده و مدیریت کلاستر پردازش داده بر اساس اکوسیستم Hadoop را برای شما بهوجود میآورد و بهترین راه برای کار و یادگیری چگونگی کارکرد بخشهای مختلف معماری ایجاد شده است.
روش دوم: از یک Sandbox استفاده کنید.
Sandbox شرکت Hortonworks، ماشین مجازی یا docker حاوی همه سرویسهای لازم برای پردازش داده و stream دادههای real-time در اکوسیستم Hadoop است که زمان بوت، راهاندازی شده و استفاده از همه ابزارهای پردازش داده را به راحتی امکانپذیر میسازد. درمورد HDP (یا همان Hortomwork Data Platform) و HDF (یا همان Hotonwork Data Flow) بیشتر بخوانید؛ دانلود و مراحل نصب را دنبال کنید. توصیه میشود فایل داکر آماده را دانلود و اجرا کنید. نسخههای دیگر این sandbox برای ماشینهای مجازی Virtualbox وVMWare هم موجود و قابل دانلود هستند. این راهکار برای بررسی سرویسهای پردازشی اکوسیستم هدوپ مسیر بهتری است چون بدون تجربه مراحل نصب و پیکربندی معماری چند لایه سیستم توزیعشده و امکان تست سرویسهای پردازش داده را به سرعت امکانپذیر میکند.
پردازش داده در اَبر دِراک
در سیستمهای پردازشی مختلف با توجه به پارامترهایی مانند دانش مورد نیاز، نحوه تولید داده، ویژگیهای داده خام موجود و… زیرساخت پردازش داده به صورت خاص بوجود میآید. تیم تحلیل داده اَبر دِراک، با توجه به این موارد، انواع مختلفی از زیرساختهای مورد نیاز را بوجود آورده است. امکانات داشبورد آماری اَبر دِراک بر اساس سرویسهای تحلیل داده ایجاد شده بر روی این زیرساختها، امکان مانیتور و درک عمیق تر عملکرد وبسایت را برای کاربران بوجود آورده است.
در ادامه مبحث زیرساخت پردازش داده در قسمتهای بعد براساس نیازهای پردازشی کسبوکارها انواع مدلها و سرویسهای پردازشی در اکوسیستم Hadoop را معرفی خواهیم کرد.


