

آنچه در این مقاله میخوانید:
- انواع سیستمهای پردازشی
- تئوری CAP چیست؟
- ارتباط بین ویژگیهای CAP
- تئوری CAP در انواع پایگاه داده NoSQL
- کار با میکروسرویسها
این تبلیغ اجاره یا فروش منزل را ببینید: «ارزان، سریع و خوب؛ دو مورد را انتخاب کنید!»
این تبلیغ بدین معنیست که یا باید خانهای ارزان را انتخاب کنید که سریع به شما تحویل داده شود،
یا خانهای ارزان و خوب انتخاب کنید که طی زمانی طولانی به شما تحویل داده میشود،
و یا خانهای خوب و با مدت زمان تحویل کوتاه انتخاب کنید، اما هزینهی زیادی بابت آن بپردازید.
منطق و مفهوم این نوع تبلیغ این است که تجمیع تمامی موارد خوب، امکانپذیر نیست.
منطق تئوری CAP نیز بیان همین مسأله در سیستمهای پردازشی است؛ یعنی نمیتوان سیستمی داشت که همزمان سه ویژگی Consistency (پایداری)، Availability (دسترسپذیری) و Partition tolerance (تحمل پذیری دربرابر جداسازی) – که به اختصار CAP نامیده میشوند – را داشته باشد.
در این مقاله میخواهیم شما را با مفهوم تئوری CAP در سیستمهای توزیعشده آشنا کرده و تأثیر این تئوری را در نحوهی طراحی، پیادهسازی و استفاده از سیستمهای توزیع شده در این زمینه بررسی کنیم.
انواع سیستمهای پردازشی
قبل از توضیح تئوری CAP، ابتدا بیایید انواع سیستمهای پردازشی را بررسی کنیم. سیستمهای پردازشی را میتوان به دو نوع Commodity و Distributed تقسیم کرد:
سیستمهای Commodity
سیستمهای Commodity یا معمولی برای انجام کارهای ساده و معمولی طراحی شدهاند که از نظر مشخصات سختافزاری مانند سیستم کامپیوتر خانگی هستند.
سیستمهای Distributed
با افزایش روز افزون حجم دادهها و عدم توانایی پاسخ سیستمهای پردازشی معمولی بدلیل کمبود منابع سختافزاری نیاز به پیدایش راهکارهای جدیدی جهت پاسخگویی به این نیاز ایجاد شد.
لازم به ذکر است که استفاده از سیستمهای پردازشی با مشخصات سختافزاری قویتر نیز جایگزین مناسبی نبوند، زیرا هزینههای سختافزاری زیادی برای نگهداری و تأمین منابع به دنبال داشتند.
در راستای حل مشکلات فوق، مجموعهای از سیستمهای معمولی در کنار هم قرار گرفتند و به هم متصل شدند تا بتوانند بدون نیاز به تهیه سختافزارهای گران قیمت، کارهای پردازشی را انجام دهند. هرکدام از این سیستمها به عنوان یک Node در نظر گرفته میشوند؛ ارتباط بین Nodeها کاملا از دید کاربر پنهان است و برای کاربر مانند یک سیستم واحد بشمار میآید. این نوع سیستم با نام سیستمهای توزیع شده شناخته میشود. سیستم توزیع شده راهکار مناسبی برای کاهش هزینه و استفاده از حداقل سختافزار به شمار میرود.
طراحی و پیادهسازی سیستمهای توزیع شده بدون در نظر گرفتن ویژگیهای لازم تقریبا کاری پیچیده و دشوار است، اما تئوری CAP توانسته معیار مناسبی را برای این منظور ارائه دهد.
تئوری CAP چیست؟
همانطور که در مقدمه بیان شد، سه ویژگی سیستم توزیع شده که قضیه CAP به آنها اشاره دارد شامل Consistency، Availability و Partition tolerance میشود. طبق این تئوری نمیتوان سیستم توزیعشدهای طراحی کرد که همزمان این سه پارامتر در آن پیادهسازی شده باشد. پس بسته به نوع داده و نحوهی مدیریت آن میبایست بهترین انتخاب را برای مدیریت دادهها انجام داد.
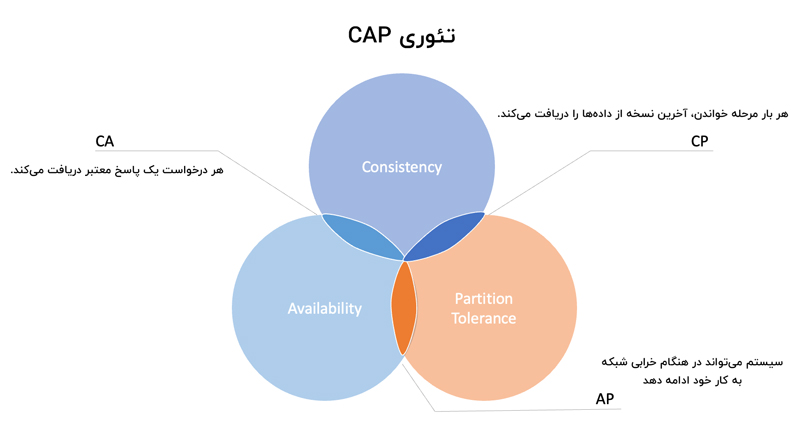
Consistency: “سازگاری” به این معنی است که همه کلاینتها، علیرغم اینکه به کدام گره یا Node (منور همان سرور است) متصل شدهاند، بتوانند دادههای یکسانی را در یک زمان مشاهده کنند. برای اینکه این اتفاق بیفتد، باید دادههایی را که روی یک گره قرار میگیرند، به سرعت روی تمام گرههای دیگر سیستم ارسال شوند.
Availability: “در دسترس بودن” به این معنی است که حتی اگر یک یا چند گره از کار بیافتند، همچنان امکان پاسخگویی به کلاینت توسط گرههای دیگر وجود دارد. به بیان دیگر، همه گرههای فعال در سیستم توزیع شده، بدون استثنا، برای هر درخواستی یک پاسخ معتبر برمیگردانند.
Partition tolerance: در سیستم توزیع شده، پارتیشن یک قطع ارتباط است؛ یعنی یک اتصال قطع شده بین دو گره را “پارتیشن” میگویند. تحمل پارتیشن (Partition tolerance) به این معنی است که علیرغم هر تعداد خرابی ارتباطی بین گرهها، سیستم به کار خود ادامه دهد و این آسیب از دید کاربر پنهان بماند.
ارتباط بین ویژگیهای CAP
نکته مهمی که لازم است بدانید این است که سیستم توزیع شده به صورت پیشفرض باید Partition Tolerance باشد. بنابراین، نمیتوان بهطور همزمان هر دو ویژگی “در دسترس بودن” و “پایداری” را در طراحی سیستمهای توزیعشده منظور کرد.
برای مثال شرایط زیر را در نظر بگیرید:
اگر مقدار یک Node در چنین مجموعهای در حال به روزرسانی باشد، در لحظهی Read/Write، آن Node از دسترس خارج میشود. سیستم توزیع شده در این حالت دیگر خاصیت Availability ندارد اما اختلالی در عملکرد کلی مجموعه ایجاد نمیشود. پس انتخاب بین پایداری (C) و دسترسپذیر بودن (Availability) است که باید با توجه به نیاز تعیین گردد.
تئوری CAP در انواع پایگاه داده NoSQL
پایگاه دادههای NoSQL (No-Relational) در پردازشهای ابری که زیر مجموعهای از سیستمهای توزیع شده هستند، نقش بسزایی دارند. پس جالب است تا نگاهی به نحوهی پیادهسازی تئوری CAP در این نوع از پایگاه دادهها بیاندازیم:
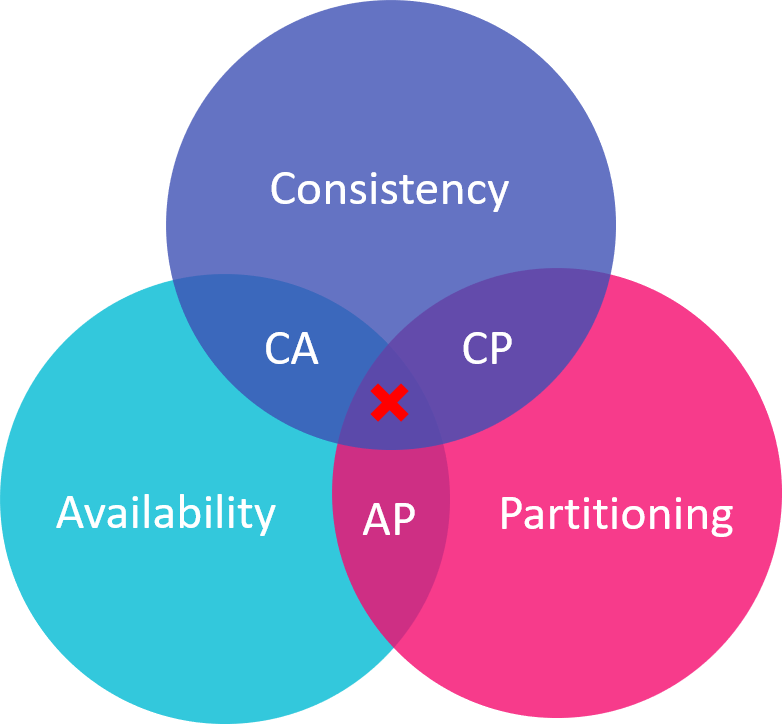
امروزه طراحی پیشفرض پایگاه دادههای NoSQL براساس ویژگی تئوری CAP (محدودیت در دارا بودن همزمان ویژگیها) به انواع زیر تقسیمبندی میشوند:
طراحی پایگاه داده CP
این دسته از پایگاه دادهها دو ویژگی پایداری (C) و تحملپذیری (P) را ارائه میدهند و ویژگی دسترسپذیری را حذف میکنند. به این معنا که اگر دادهی یک Node بهروزرسانی نشده باشد، آنگاه آن Node از دسترس خارج میشود تا نتوان درخواستی را به آن Node ارسال کرد. پایگاه دادهی Mongo مثالی برای این نوع عملکرد است.
طراحی پایگاه داده AP
ویژگی دسترسپذیری (A) و تحملپذیری (P) در برابر جداسازی Nodeها بدون امکان پایداری ارائه میشود. اگر به هر دلیلی بخشی از مجموعه از کار افتاد، هیچ Node یا گرهای از دسترس خارج نمیشود. اما، دیگر از نظر مقداری نمیتواند حاوی مقدار بهروزرسانی شده باشد و تنها پس از رفع مشکل، Nodeهای آسیبدیده خود را با مقادیر جدید سینک میکنند. به عنوان مثال Cassandra یکی از این نوع پایگاه دادهها محسوب میشود.
طراحی پایگاه داده CA
از آنجایی که این نوع از طراحی پایگاه دادهها دارای ویژگی پیشفرض سیستمهای توزیع شده یعنی Partition Tolerance نیستند، نقشی در پیادهسازی طراحی پایگاه داده برای این نوع از سیستمهای پردازشی ندارند.
در انتها لازم به ذکر است که در طراحی هر کدام از گروههای فوق، میتوان چارچوبها را بسته به نیاز تغییر داد.
کار با میکروسرویسها
میکروسرویسها اجزای برنامهای هستند که بهطور مستقل با هم جفت میشوند و و از طریق یک شبکه با یکدیگر ارتباط برقرار میکنند. از آنجایی که میتوان میکروسرویسها را هم در سرورهای ابری و هم در مراکز داده داخلی اجرا کرد، از آنها برای ایجاد برنامههای ترکیبی و چند ابری استفاده میکنند.
درک قضیه CAP میتواند در طراحی برنامههای کاربردی مبتنی بر میکروسرویس و انتخاب بهترین پایگاه داده برای آن کمک کند. برای مثال، اگر برنامه شما نیاز به تکرار سریع مدل داده دارد، اما میتواند سازگاری نهایی را تحمل کند، پایگاه دادهای از نوع AP مانند Cassandra یا Apache CouchDB میتواند مناسب باشد. ولی اگر برنامه شما به شدت به سازگاری دادهها بستگی داشته باشد، مانند یک برنامه تجارت الکترونیک یا یک سرویس پرداخت، بهتر است از پایگاه داده رابطهای مانند PostgreSQL استفاده کنید.
تئوری CAP مفهوم واقع گرایانهای را ارائه میدهد که به مهندسان و توسعهدهندگان حوزه IT کمک میکند تا سیستمها و برنامههای کاربردی را با توجه به هدف ساخت آنها، طراحی کنند. امیدواریم با مطالعه کامل این مقاله، دلیل اصلی در دسترس نبودن همزمان سه ویژگی مهم پایداری، دسترسپذیری و تحملپذیری را به خوبی درک کرده باشید و بتوانید بهترین استفاده را از این تئوری در طراحیهای خود ببرید.


